May 2026
Circuits Updates — May 2026
A short update on understanding features through downstream connections.

Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
We train Claude to translate its internal state into natural language.
HeadVis
We develop an interactive visualization tool to help us understand the behaviors of attention heads in language models.
April 2026
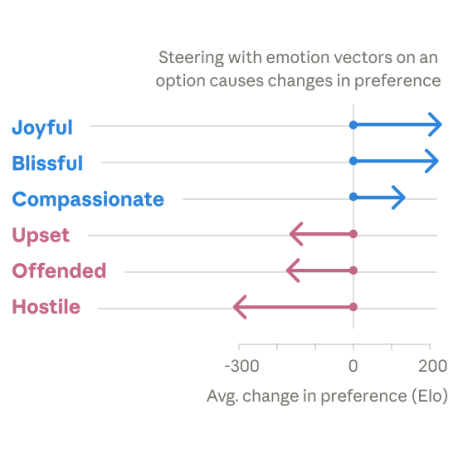
Emotion Concepts and their Function in a Large Language Model
We find representations of emotion concepts in Claude Sonnet 4.5 and show that they causally influence its outputs.
December 2025
Circuits Cross-Post — Activation Oracles
We train language models to answer questions about their own activations in natural language.
November 2025
Circuits Updates — November 2025
A short update on harm pressure.
October 2025

Emergent Introspective Awareness in Large Language Models
We find evidence that language models can introspect on their internal states.
Circuits Updates — October 2025
Small updates on visual features and dictionary initialization.
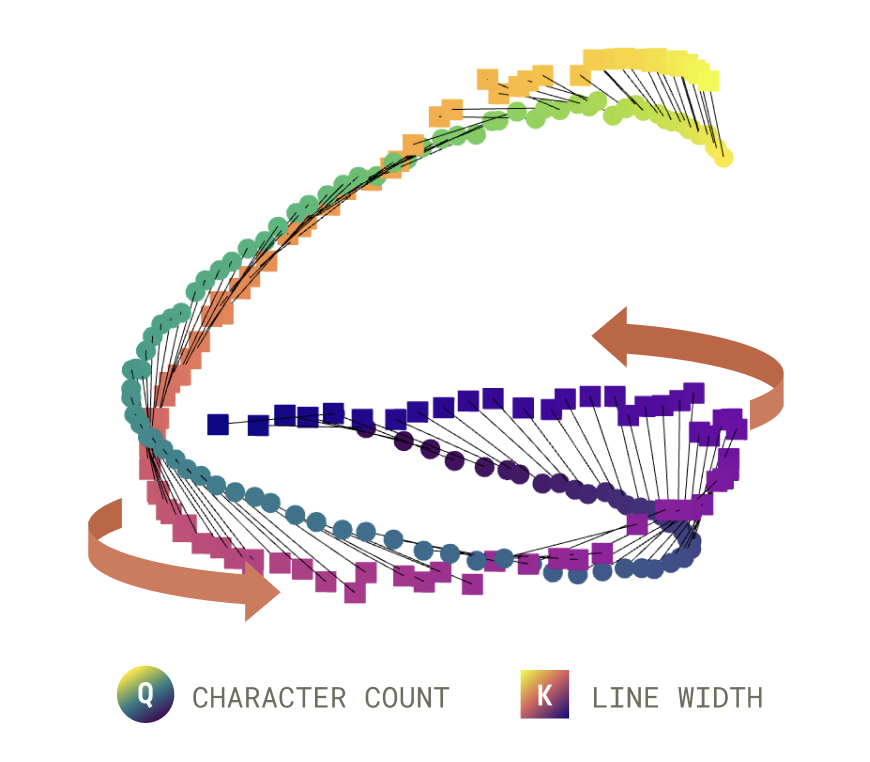
When Models Manipulate Manifolds: The Geometry of a Counting Task
We find geometric structure underlying the mechanisms of a fundamental language model behavior.
September 2025
Circuits Updates — September 2025
A small update on features and in-context learning.
August 2025
Circuits Updates — August 2025
A small update: How does a persona modify the assistant’s response?
July 2025
A Toy Model of Mechanistic (Un)Faithfulness
When transcoders go awry.
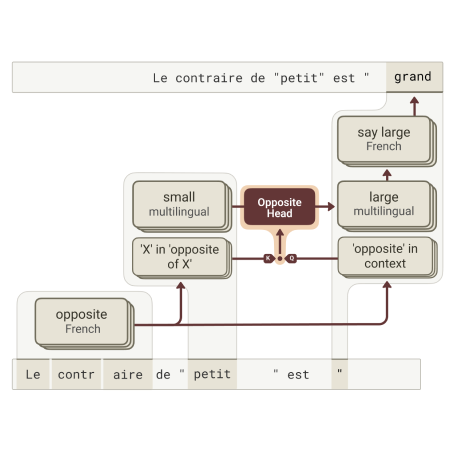
Tracing Attention Computation Through Feature Interactions
We describe and apply a method to explain attention patterns in terms of
feature interactions, and integrate this information into attribution graphs.
A Toy Model of Interference Weights
Unpacking "interference weights" in some more depth.
Sparse mixtures of linear transforms
We investigate sparse mixture of linear transforms (MOLT), a new approach to transcoders.
Circuits Updates — July 2025
A collection of small updates: revisiting A Mathematical Framework and applications of
interpretability to biology.
Automated Auditing
A note on using agents to perform automated alignment audits, including using interpretability
tools.
April 2025
Circuits Updates — April 2025
A collection of small updates: jailbreaks, dense features, and spinning up on interpretability.
Progress on Attention
An update on our progress studying attention.
March 2025
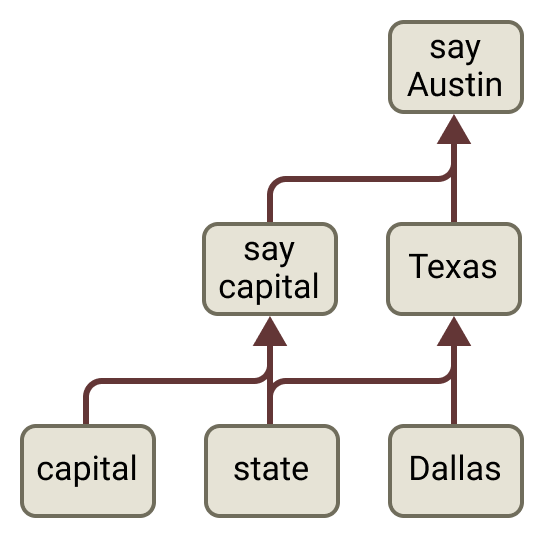
On the Biology of a Large Language Model
We investigate the internal mechanisms used by Claude 3.5 Haiku — Anthropic's lightweight
production model — in a variety of contexts.
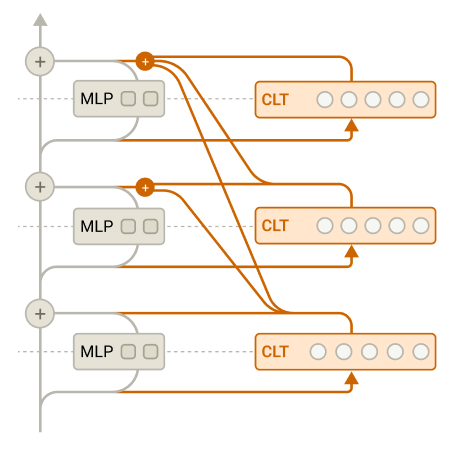
Circuit Tracing: Revealing Computational Graphs in Language Models
We describe an approach to tracing the "step-by-step" computation involved when a model responds
to a single prompt.
February 2025
Insights on Crosscoder Model Diffing
A preliminary note on using crosscoders to diff models.
January 2025
Circuits Updates — January 2025
A collection of small updates: dictionary learning optimization techniques.
December 2024
Stage-Wise Model Diffing
A preliminary note on model diffing through dictionary fine-tuning.
October 2024
Sparse Crosscoders for Cross-Layer Features and Model Diffing
A preliminary note on a way to get consistent features across layers, and even models.
Using Dictionary Learning Features as Classifiers
A preliminary note comparing feature-based and raw-activation based harmfulness classifiers.
September 2024
Circuits Updates — September 2024
A collection of small updates: investigating successor heads, oversampling data in SAEs.
August 2024
Circuits Updates — August 2024
A collection of small updates: interpretability evals, reproducing self-explanation.
July 2024
Circuits Updates — July 2024
A collection of small updates: five hurdles, linear representations, dark matter, pivot tables,
feature sensitivity.
June 2024
Circuits Updates — June 2024
A collection of small updates: topk and gated SAE investigation.
May 2024

Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Using a sparse autoencoder, we extract a large number of interpretable features from Claude 3
Sonnet. Some appear to be safety-relevant.
April 2024
Circuits Updates — April 2024
A collection of small updates from the Anthropic Interpretability Team.
March 2024
Circuits Updates — March 2024
A collection of small updates from the Anthropic Interpretability Team.
Reflections on Qualitative Research
Some opinionated thoughts on why interpretability research may have
qualitative aspects be more central than we're used to in other fields.
February 2024
Circuits Updates — February 2024
A collection of small updates from the Anthropic Interpretability Team.
January 2024
Circuits Updates — January 2024
A collection of small updates from the Anthropic Interpretability Team.
October 2023
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Using a sparse autoencoder, we extract a large number of interpretable features from a one-layer
transformer.
July 2023
Circuits Updates — July 2023
A collection of small updates from the Anthropic Interpretability Team.
May 2023
Circuits Updates — May 2023
A collection of small updates from the Anthropic Interpretability Team.
Interpretability Dreams
Our present research aims to create a foundation for mechanistic
interpretability research. In doing so, it's important to keep sight of what we're trying to lay
the foundations for.
Distributed Representations: Composition & Superposition
An informal note on how "distributed representations" might be understood
as two different, competing strategies — "composition" and "superposition" — with quite
different properties.
March 2023
Privileged Bases in the Transformer Residual Stream
Our mathematical theories of the Transformer architecture suggest that
individual coordinates in the residual stream should have no special
significance, but recent work has shown that this observation is false in practice.
We investigate this phenomenon and provisionally conclude that the per-dimension normalizers in
the Adam optimizer are to blame for the effect.
January 2023
Superposition, Memorization, and Double Descent
We have little mechanistic understanding of how deep learning
models overfit to their training data, despite it being a
central problem. Here we extend our previous work on toy models
to shed light on how models generalize beyond their training
data.
September 2022
Toy Models of Superposition
Neural networks often seem to pack many unrelated concepts into a single
neuron - a puzzling phenomenon known as 'polysemanticity'. In our latest interpretability work,
we build toy models where the origins and dynamics of polysemanticity can be fully understood.
June 2022
Softmax Linear Units
An alternative activation function increases the fraction of neurons which
appear to correspond to human-understandable concepts.
Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases
An informal note on intuitions related to mechanistic interpretability.
March 2022
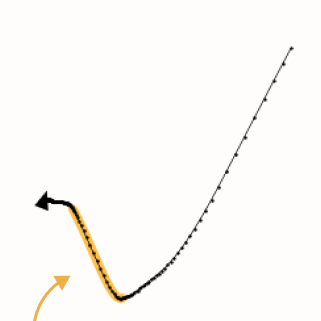
In-Context Learning and Induction Heads
An exploration of the hypothesis that induction heads are the primary
mechanism behind in-context learning. We also report the existence of a previously unknown phase
change in transformers language models.
December 2021
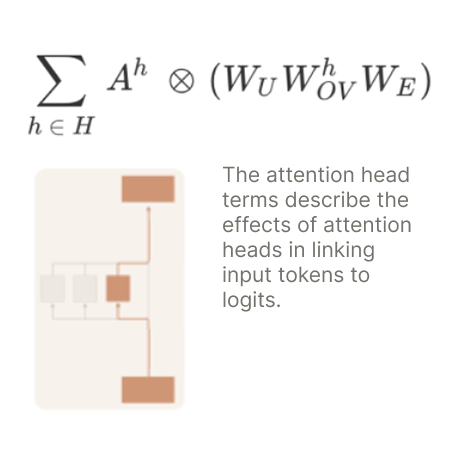
A Mathematical Framework for Transformer Circuits
Our early mathematical framework for reverse engineering models,
demonstrated by reverse engineering small toy models.
Exercises
Some exercises we've developed to improve our understanding of how neural
networks implement algorithms at the parameter level.
Videos
Very rough informal talks as we search for a way to reverse engineering
transformers.
PySvelte
One approach to bridging Python and web-based interactive diagrams for
interpretability research.
Garcon
A description of our tooling for doing interpretability on large models.
March 2020 - April 2021

Original Distill Circuits Thread
Our exploration of Transformers builds heavily on the original Circuits
thread on Distill.