
Transformer-based language models involve two main kinds of computations: multi-layer perceptron (MLP) layers that process information within a context position, and attention layers that conditionally move and process information between context positions. In our recent papers we made significant progress in breaking down MLP computation into interpretable steps. In this update, we fill in a major missing piece in our methodology, by introducing a way to decompose attentional computations as well.
Our prior work introduced attribution graphs as a way of representing the forward pass of a transformer as an interpretable causal graph. These graphs were built on top of (cross-layer) transcoders, a replacement for the original model’s MLP layers that use sparsely active “features” in place of the original MLP neurons. The features comprise the nodes of the attribution graphs, and edges in the graphs represent attributions – the influence of a source feature on a target feature in a later layer.
The attribution graphs in our initial work were incomplete, in that they omitted key information about attentional computations. The feature-feature interactions we studied – the edges in the graph – are mediated by attention heads that carry information between context positions. However, we did not attempt to explain why the attention heads attended to a particular context position. In many cases, this has prevented us from understanding the crux of how models perform a given task.
In this update, we describe a method to address this issue by extending attribution graphs so they can explain attention patterns. Our method is centered on “QK attributions,” which describe attention head scores as a bilinear function of feature activations on the respective query and key positions. We also describe a way to integrate this information into attribution graphs, by computing the contribution of different attention heads to graph edges.
We provide several case studies of this method in action. Some of these examples confirmed existing hypotheses we described in Biology, which we could not validate at the time:
We also surfaced new, unexpected mechanisms:
The case studies here are our first attempts at applying the method, and we expect more discoveries to result in future work.
We believe the addition of QK attributions is a significant qualitative improvement on our original attribution graphs, unlocking analyses that were previously impossible. However, there remain many open research questions regarding attentional circuits, which we describe at the end of the post.
Transcoders only ever read and write information within the same context position – however, transformer models also contain attention layers, which carry information across context positions. Thus, the influence between any two transcoder features is mediated by attention layers
To make attribution a clearly defined operation, we designed our attribution graphs so that interactions between features are linear. One of the key tricks in doing this is to freeze the attention patterns, treating them as a constant linear operation (and ignoring why they have those attention patterns). This allows us to trace the effect of one feature on another through attention heads. This could potentially involve multiple attention heads operating in parallel, and also compositions of attention heads. The resulting attribution is a sum of attributions corresponding to the features being mediated by different sequences of attention heads.
But freezing attention patterns and summing over heads like this means our attribution graphs are “missing” key information about attentional computation, in two respects:
In our original paper, we pointed out that for many prompts, this missing QK information renders attribution graphs useless. In particular, for many prompts, the question of which head(s) mediated an edge, and why those heads attended where they did, is the crux of the computation. We provide several examples of this failure mode later in the paper and demonstrate how our method fills in the missing information.
Explaining the source of an attention head’s attention pattern. The core insight underlying our method is the fact that attention scores (prior to softmax) are a bilinear function of the residual stream at the query and key positions. Thus, if we have a decomposition of the residual stream as a sum of feature components, we can rewrite the attention scores as a sum of dot products between feature-feature pairs (one on the query position, one on the key position). We call this decomposition “QK attribution” and describe in more detail how we compute it below. Note that the same strategy was used by
Explaining how attention heads participate in attribution graphs. Explaining the source of each head’s attention scores is insufficient on its own; we also must understand how the heads participate in our attribution graphs. To do so, for each edge in an attribution graph, we keep track of the extent to which that edge was mediated by different attention heads. To achieve this, (cross-layer) transcoders on their own are not adequate; we explain this issue and how to resolve it below.
QK attributions are intended to explain why each head attended where it did. In this section, we assume that we have trained sparse autoencoders (SAEs) on the residual stream of each layer of the model (though there are alternative strategies we could use; see below).
In a standard attention layer, a head’s attention score at positions (

The sum of these terms adds up to the attention score.
Note that in some architectures, there may exist a normalization step between the residual stream and the linear transformations
Once we have computed these terms, we can simply list them ordered by magnitude. Each term is an interaction between a query-side and key-side component, which can be listed side-by-side. For feature components, we label them with their feature description and make them hoverable in our interactive UI so that their “feature visualization” can be easily viewed.

One limitation of this approach is that it does not directly explain the attention pattern itself, which involves competition between the attention scores at multiple context positions – to explain why an attention head attended to a particular position, it may be important to understand why it didn’t attend to other positions. Our method gives us information about QK attributions at all context positions, including negative attributions, so we do have access to this information (and we highlight some interesting inhibitory effects in some of our later examples). However, we do not yet have a way of automatically surfacing the important inhibitory effects without manual inspection. While addressing this limitation is an important direction for future work, we nevertheless find that our attention score decompositions can be interpretable and useful.
QK attributions help us understand the source of each head’s attention pattern. For this understanding to be useful to us, we need to understand what these attention patterns were used for. Our strategy is to enrich our attribution graphs with “head loadings” for each edge, which tell us the contributions that each attention head made to that edge.
It turns out that computing the contributions of attention heads to graph edges is difficult to achieve with transcoder-based attribution graphs. This is because when transcoder features are separated by L layers, the number of possible attention head paths between them grows exponentially with L
We can sidestep this issue by using a method that forces each edge in a graph to be mediated only by attention head paths of length 1. This can be achieved using several different strategies, which we have experimented with:

For now, we have adopted the third strategy. The other two methods accumulate error in the residual stream across layers, which we have found leads to greater overall reconstruction errors, resulting in attributions that are dominated by error nodes.
It’s important to note that an edge may still be mediated by multiple heads at a given layer! However, it can no longer be mediated by chains of heads across multiple layers.
Once we have trained SAEs (or a suitable alternative) as described above, we can compute attention head loadings for graph edges – the amount that each head is responsible for mediating that edge. Any edge between two SAE features in adjacent layers is a sum of three terms: an attention-mediated component, an MLP-mediated component, and a residual connection-mediated component.
Let source and target feature at positions
The sum over heads runs over all the heads in the source feature’s layer (which is one layer prior to the target feature’s). Each term in this sum represents the contribution (head loading) of a specific attention head to this edge. We compute and store these terms separately and surface them in our UI .
In this section, we will show how head loadings and QK attributions can be used to understand attentional computations that were missing in our previous work.
Claude 3.5 Haiku completes the prompt:
I always loved visiting Aunt Sally. Whenever I was feeling sad, Aunt
with “Sally”. In our original paper, the attribution graph for this prompt shows a strong direct edge from “Sally” features (on the “Sally” token) to the “Sally” logit on the final token. In other words, the model said “Sally” because it attended to the “Sally” token. This is not a useful explanation of the model’s computation! In particular, we’d like to know why the model attended to the Sally token and not some other token.

Prior work has suggested that language models learn specific attention heads for induction, but it’s unclear how these heads perform the induction mechanism. In this example:
We used QK attributions to investigate both questions.
To answer the first question, we traced the input edges of the “Sally” logit node and “say Sally” features on the second “Aunt token.” We find that these nodes receive inputs from “Sally” features on the “Sally” token, and that these edges are mediated by a small set of attention heads. When we inspect the QK attributions for these heads, we find interactions between:

Thus, the QK circuit for these induction-relevant heads appears to combine two heuristics: (1) searching for any name token at all, (2) searching specifically for names of aunt/uncles.

We performed interventions with this mechanism to test our hypothesis. We begin by choosing a set of heads with high head loadings (roughly 3–10% of heads

To answer the second question, we looked at all edges in the pruned graph between the first “Aunt” token and the first “Sally” token. There are many edges which connect features between these two tokens, but most of them appear to be doing the same thing: connecting an “Aunt” feature to a “last token was Aunt” feature. If we look at the head loadings for these edges, nearly all high-weight edges are mediated by the same subset of heads.
Next, we looked at the QK attributions for these heads. All the relevant heads’ attention scores seem to be predominantly explained by the same query-key interactions – query-side “first name” features interacting with key-side “title preceding name” features (activating on words like “Aunt”, “Mr.”, etc.).

Note that so far, we’ve ignored the effect of positional information on attention pattern formation, but we might expect it to be important in the case of induction – for instance, if there are multiple names with titles mentioned in the context, the “Sally” token should attend to the most recent one. We leave this question for future work.
In the examples above, we depict attention scores as being driven by an interaction between a single type of query-side and key-side feature. In reality, there are many independent query feature / key feature interactions that contribute. Below we show an example where some of the multiple independent interactions are particularly interesting and interpretable.
In the prompt
I always loved visiting Aunt Mary Sue. Whenever I was feeling sad, Aunt Mary
which Haiku completes with “Sue”, we see that query-side “Mary” features interact with key-side “token after ‘Mary’” features, and, independently, we see that query and key-side “Name of Aunt/Uncle” features interact with one another. Notably, we do not see strong contributions from the cross terms (e.g. “Mary” interacting with “Name of Aunt/Uncle”) – that is, the rank of this QK attributions matrix is at least 2. In reality, even this picture is a dramatic oversimplification, and we see several other kinds of independently contributing QK interactions (for instance, the bias term on the query side interacting with generic name-related features on the key side, suggesting that these heads have a general bias to attend to name tokens).

Haiku completes the prompt Le contraire de "petit" est " with “grand” (“The opposite of ‘small’ is ‘big’”, in French).
In our original paper, the attribution graph for this prompt showed edges from features representing the concept of “small” onto features representing the concept of “large.” Why does this small-to-large transformation occur? We hypothesized that this may be mediated by “opposite heads,” attention heads that invert the semantic meaning of features. However, we were not able to confirm this hypothesis, or explain how such heads know to be active in this prompt.

After computing head loadings and QK attributions, we see that the small-to-large edges are mediated by a limited collection of attention heads. When we inspect the QK attributions for these heads, we find two interesting interactions between the following kinds of features:

This suggests that the model mixes at least two mechanisms:

We find that inhibiting the query-side “opposite” features significantly reduces the model’s prediction of “large” in French, and causes the model to begin predicting synonyms of “small” such as “peu” and “faible”. A similar (but lesser) effect occurs when we inhibit “adjective” features on the key side.

Haiku completes the prompt
Human: In what year did World War II end?
(A) 1776
(B) 1945
(C) 1865
Assistant: Answer: (
with “B”.
In our original paper, the attribution graph showed a direct edge from “B” features on the “B” token to the “B” logit on the final token (or to “say B” features in the final context positions, which themselves upweight the “B” logit). Again, this is not a helpful explanation of the model’s computation! We want to know how the model knew to attend to the “B” option and not one of the other options. We hypothesized (inspired by

How does the model know to attend to the tokens associated with option B? To answer this question, we inspected the head loadings for these edges and found a fairly small collection of heads that mediate them. Inspecting the QK attributions for these heads, we found interaction between:

These interactions suggest that these heads have an overall inclination (due to the query-side bias contribution) to attend to correct answers at all times, and an even stronger inclination to do so when the context suggests that the model needs to provide a multiple choice answer.

We validated this mechanism with the following perturbation experiments:
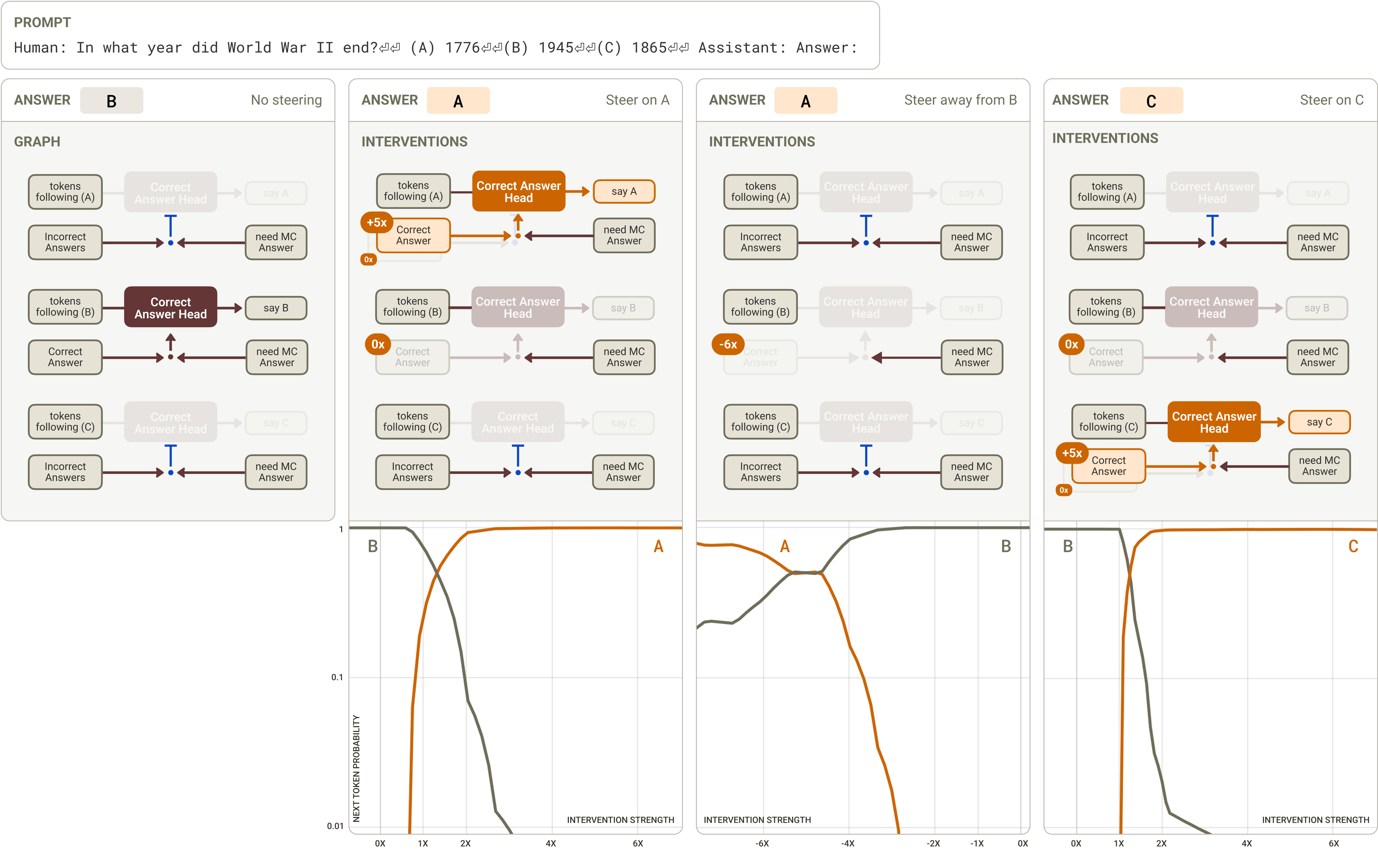
To complete our understanding of the model’s computation on this prompt, we would like to understand how the “correct answer” features are computed in the first place. The graph suggests that these features emerge from a combination of two sets of features: “1945 (in the context of ‘the end of World War 2’)” features over the same token, and “end of World War 2” features over the relevant tokens in the question. Unfortunately, we are not able to understand the mechanism in more depth as the cross-token inputs are obscured by error nodes.
Haiku completes the prompt
Human: Answer with yes or no. The color of a banana is yellow?
Assistant:
with “Yes”. If yellow is replaced with red, it answers “No”.
How does the model distinguish between the correct and incorrect statements? Surprisingly, we did not find clear evidence of our initial hypothesis: that the model first explicitly computes color + banana = yellow and then matches the stated answer, yellow or red, with the computed answer. Instead, we found distinct attention heads which directly determine the concordance or discordance of the stated answer with respect to the posed computation.
Tracing back from the “Yes” and “No” responses in the respective attribution graphs, we observed “correct answer” features (in the yellow case), and “false statements about equalities” (in the red case). These in turn received inputs from a “plausible properties of things” feature (in the yellow case) and a “discordant statements” feature (in the red case). These features are only active in their respective prompts, and not the other.

Interestingly, when we trace back from the “plausible properties” and “discordant statements” features, we observe that they receive strong inputs from features on the “banana” token. These features include a variety of fairly generic noun-related features (such as “nouns after descriptors”) in addition to some of the “banana” features. The specific input features vary somewhat between the two prompts, but not in a way that makes it clear why they would be triggering “plausible properties” in one case and “discordant statements” in another.

However, we noticed that the attention heads carrying these edges were different in the two cases. One set of heads (“concordance heads”) carried the edge in the yellow case, while another set of heads (“discordance heads”) carried the edge in the red case.
When we inspected the QK attributions for these heads, we saw that these heads were driven by interactions between the relevant color features (yellow or red) on the query side, and banana features on the key side. Banana-yellow interactions contributed positively to the concordance heads’ attention score and negatively to the discordance heads’ attention score; banana-red interactions did the reverse.

Thus, we arrived at the following understanding of the circuit.

To test the mechanistic faithfulness of this circuit, we performed causal interventions on the concordance and discordance heads. We tested whether steering on the QK-attributed features could shift the attention patterns of the heads and the resulting response of the model. Using the ‘banana is yellow’ prompt, we steered the query-side input to the concordance and discordance heads, positively steering on one ‘red’ feature with concurrent negative steering on one ‘yellow’ feature. This was sufficient to reduce attention of the concordance heads from the yellow context position to the banana context position, while increasing attention of the discordance heads between the same positions. In turn, this targeted intervention was sufficient to flip the model’s response from Yes to No, even at moderate steering values. Additional interventions showed that the scaled output of even a single concordance or discordance head is sufficient to flip the response, and that this effect is strengthened through the combination of multiple such heads.

We have also observed that the same heads play similar roles in checking other kinds of correctness. For instance, consider the prompt
Human: Answer with yes or no. 18+5=23?
Assistant:
Which the model completes with “Yes”. If 5 is replaced with 6, it answers “No”.
When we inspected the attention patterns from the “23” token to the second operand token (“5” or “6”), we observed that the same “concordance heads” and “discordance heads” appear to discriminate between correct and incorrect cases in the expected way (higher attention pattern for the concordance head in the correct case, and vice versa for the discordance head).
When we inspect the QK attributions for these heads, we observed “numbers separated by an interval of 5” features on the query side interacting with “5” and “6” features on their respective prompts. In the “5” case, the contributions of these interactions to the attention score were positive for the concordance heads and negative for the discordance heads. In the “6” case, the signs were reversed.

Notably, in this case we also did not see clear evidence of the model first explicitly computing the answer (23 or 24, respectively), and then matching it with the stated answer, 23. The model instead identifies a “property” of the sum x+y, by using its ability to recognize sequences incrementing by 5 to determine that the second term should be 5, and uses the concordance and discordance heads to detect that property. These observations align with recent results that used edge attribution patching to identify consistency heads in the early-to-mid layers of open source models, and further support the conclusion that there are distinct mechanisms for validating versus computing answers
Thus, our preliminary conclusion is that these heads use their QK circuits to check for concordant properties between features on the query and key tokens. For the concordance head, if there is a QK match, it attends to the relevant key token.
More work is needed to understand the scope and generality of which kinds of properties these heads can check for, and what exactly the OV circuit is using as input substrate to transform into (in)correctness-related outputs.
The work most closely related to ours is
Other papers have studied QK circuit mechanisms using carefully designed patching experiments. For instance,
Head loadings and QK attributions provide a simple, albeit somewhat brute force, way of explaining where the attention patterns came from that facilitated edges in an attribution graph. This ability has proved useful in understanding behavior that was previously left unexplained, and we plan on investing in it further. We’re interested in simply applying this method to a broader range of examples to better understand attention “biology” – some applications of particular interest include understanding entity binding, state tracking, and in-context learning.
We’re also interested in improving the methodology. Some questions of interest include:
We’d be excited to see the community explore these and related questions, and to extend the open-source attribution graph repo and interface to include attentional attributions.
We thank Julius Tarng for valuable assistance with the figures, and Adam Jermyn for valuable conceptual discussions about attention.
For attribution in academic contexts, please cite this work as
Kamath, Ameisen, et al., "Tracing Attention Computation", Transformer Circuits, 2025.
BibTeX citation
@article{kamath2025tracing, author={Kamath, Harish and Ameisen, Emmanuel and Kauvar, Isaac and Luger, Rodrigo and Gurnee, Wes and Pearce, Adam and Zimmerman, Sam and Batson, Joshua and Conerly, Thomas and Olah, Chris and Lindsey, Jack}, title={Tracing Attention Computation Through Feature Interactions}, journal={Transformer Circuits Thread}, year={2025}, url={https://transformer-circuits.pub/2025/attention-qk/index.html} }